Arbre Binaire de Recherche et Tas¶
Warning
Ce cours a été automatiquement traduit des transparents de M.Noyer par Lorentzo et Elowan et mis en forme par Mehdi, nous ne nous accordons en aucun cas son travail, ce site à pour seul but d’être plus compréhensible pendant les périodes de révision que des diaporamas.
Crédits
- "Option informatique MPSI, MP/MP*", Roger Mansuy, paru chez Vuibert.
- Wikipédia : Tas, Tas binaires, Tri par tas
- OpenClassRoom Arbres binaires de recherche
Arbres binaires de recherche¶
ABR¶
BST¶
Définition: Arbre binaire de recherche
Binary search trees (BST)
Un arbre binaire de recherche (ABR) sur un type totalement ordonné est un arbre binaire tel que pour tout nœud interne, les étiquettes apparaissant dans le sous-arbre gauche (resp.droit) sont strictement\(^{a.}\) inférieures (resp. supérieures) à celle la racine.
\(a.\) Selon la mise en œuvre de l’ABR, on pourra interdire ou non des clés de valeur égale.
Figure – Un ABR
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A((8))-->B((3))
A-->C((10))
B-->D((1))
B-->E((6))
C-->H(( ))
C-->G((14))
E-->J((4))
E-->K((7))
G-->O((13))
G-->F(( ))
style H display:none
style F display:noneLes étiquettes de gauche ont des valeurs plus petites que celle de la racine, celle de droite sont plus grandes
DSF¶
On peut facilement récupérer les clés d’un arbre binaire de recherche dans l’ordre croissant en réalisant un parcours en profondeur infixe.
Contre-exemple
Figure – Un arbre binaire qui n’est pas un ABR
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A((6))-->B((4))
A-->C((5))Passage liste ordonnée / ABR¶
À une liste ordonnée correspondent plusieurs ABR.
Exemple
Figure – Un ABR pour représenter [4,5,6]
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A((6))-->B((5))
A -->Z(( ))
B-->C((4))
B-->W(( ))
style Z display:none
style W display:noneFigure – Un ABR équilibré pour représenter [4,5,6]
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A((5))-->B((6))
A-->C((4))Figure – Un ABR pour représenter [4,5,6]
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A -->Z(( ))
A((4))-->B((5))
B-->W(( ))
B-->C((6))
style Z display:none
style W display:noneInmplémentation¶
Type de données pour l'ABR¶
Nous utiliserons le type suivant:
- Une feuille est implémentée par
N(x, Nil, Nil), - Un nœud d’arité \(1\) par
N(x, t, Nil)ouN(x, Nil, t)avecxettde type convenable. - Une telle structure modélise les arbres binaires, pas seulement les ABR. C’est lors de la création d’un arbre que nous ferons attention à ce qu’il respecte la contrainte d’ordre.
Primitives pour l'ABR¶
- Une fonction de création d’un ABR à partir d’une liste.
- Une fonction d’insertion d’une valeur dans un ABR.
- Une fonction de recherche d’une valeur dans un arbre.
- Une fonction de suppression d’une valeur dans un arbre.
Insérer sous une feuille¶
| Insérer sous une feuille | |
|---|---|
- Le choix qui est fait ici est celui d’un ABR sans étiquettes de mêmes valeurs (pas de doublon).
- On insère la nouvelle valeur sous une feuille.
- On pourrait aussi insérer \(x\) à la racine:
- "Couper" l’arbre en deux sous-ABR \(g\) , \(d\) contenant respectivement les éléments plus petits et plus grands que \(x\).
- construire l’arbre
N(x, g, d)
Complexité de l’insertion sous une feuille¶
Description informelle pour un arbre de hauteur \(h\) à \(n\) nœuds.
- On descend le long d’une branche jusqu’à la feuille.
- Il y a \(O(h)\) pour cette descente. Pour chaque nœud interne, les opérations hors appel récursif sont à coût constant.
- Dans le cas d’arrêt, le coût est également constant.
- Donc complexité en \(O(h)\).
- On comprend l’intérêt de "contrôler" \(h\). En pratique, on essaye de conserver \(h \leq C \log(n)\) pour une certaine constante. Si on arrive à maintenir cette contrainte au fil des insertions, on obtient un arbre équilibré.
Création d'ABR¶
| Créer un ABR à partir d’une liste | |
|---|---|
Figure – ABR obtenu par create([1;4;2;3]);;
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A((3))-->B((2))
A-->C((4))
B-->D((1))
B-->E(( ))
style E display:noneListe triée¶
Si la liste est déjà triée, on obtient une liste chaînée.
Figure – ABR obtenu par create([1;4;2;3]);;
%%{ init: { 'flowchart': { 'curve': 'linear' } } }%%
graph TB;
A((4))-->B((3))
A -->Z(( ))
B-->C((2))
B-->W(( ))
C-->D((1))
C-->R(( ))
style Z display:none
style W display:none
style R display:noneComplexité de la création d'ABR¶
- Si la liste est déjà triée, l’ABR n’a qu’une branche.
- Pour une liste triée de longueur \(n\), la complexité vérifie une relation de la forme
- On voit l’intérêt de maintenir un certain équilibre dans l’arbre au moment des insertions.
Utilité de l’équilibrage des arbres¶
- À priori, cela ne semble pas si grave d’avoir une liste chaînée et non un bel arbre binaire "équilibré".
- Mais les opérations sur les ABR (insertion, suppression, recherche) ont une complexité au pire qui dépend de la hauteur...
- ... d’où l’idée qu’il faut limiter la hauteur des arbres lors de l’insertion.
- C’est le principe du rééquilibrage des ABR.
Création d’un arbre équilibré à partir d’une liste¶
- Un arbre \(A\) est dit équilibré lorsque \(h(A) = O(\log_{}(|A|))\)
- Exemple arbres AVL: pour chaque nœud, la différence entre les hauteurs de ses fils (l’un éventuellement vide) est \(0\), \(1\) ou \(−1\).
-
On peut établir que, dans un AVL de taille \({|A| = n} \implies {\frac{3}{2}\log_{2}(n+ 1) \geq h(A)}\) (cf TD).
-
Autre exemple : arbres Rouge-Noir (cf TD).
- Dans un arbre équilibré, insérer \(x\) se fait en \(O(\log_{2}(n))\) appels internes au pire plus un nombre borné d’autres opérations en \(\Theta(1)\) .
- Si on maintient le caractère équilibré (le rééquilibrage a un coût logarithmique -admis-), le coût de la création à partir d’une liste est donc de l’ordre de \(\Theta \left(\sum\limits_{k=1}^{n}\log_{2}(k)\right) = \Theta\left(\log_{2}(n!)\right) = \Theta\left(n\log_{2}(n)\right)\)
Rechercher¶
- Si \(x\) est égal à la racine de \(t\), c’est bon. Sinon on cherche récursivementdans le sous arbre gauche lorsque \(x\) es plus petit que la racine, et à droite sinon.
- Si \(x\) est à la profondeur \(k\), il y a \(k\) appels internes pour le trouver.
- Si \(x\) n’est pas dans l’arbre, il y a au pire \(h(t)\) appels internes.
Suppression¶
Opération de fusion¶
On veut "fusionner" deux ABR \(G\) et \(D\) tels que les étiquettes de \(G\) sont toutes plus petites que celles de \(D\). Ceci afin d’obtenir un ABR unique construit à partir des nœuds des deux arbres.
Dans cette fusion, la racine de l’arbre gauche devient systématiquement la racine de l’arbre retourné. On aurait pu privilégier l’arbre droit.
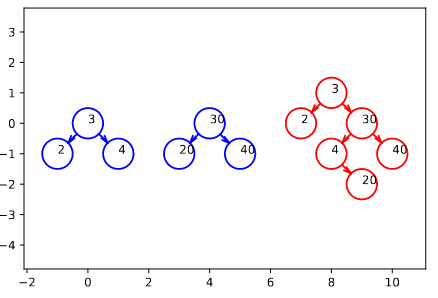
Figure – En rouge, la fusion des deux arbres bleus
Correction de la fusion¶
Preuve par induction
On montre que si on fusionne deux ABR \(a, b\) tels que \(max a ≤ min b\), alors le nouvel arbre formé est un ABR contenant toutes les étiquettes de \(a, b\).
- Cas de base : si un des deux arbres est vide, on renvoie l’autre. C’est un ABR par hyp. et il contient bien toutes les étiquettes des deux arbres.
- Hérédité. Soient \(a = N(x, g_a, d_a)\) et \(b = N(y , g_b, d_b)\) non vides avec \(\max a \leq \min b\).
- Notre hypothèse d’induction (HI) est que la fusion d’un sous-terme immédiats de \(a\) avec un sous-terme immédiat de \(b\) est un ABR contenant toutes les étiquettes de ses deux sous-termes.
- La racine du nouvel arbre est \(x\) et elle est plus grande que toutes les étiquettes de son fils gauche \(g_a\) (puisque \(a\) est un ABR).
- Le fils droit est \(d = N(y , merge(d_a, g_b), d_b)\). Par (HI) la fusion
merge(da, gb)est un ABR avec toutes les étiquettes de \(d_a, g_b\). - Comme \(y\) est supérieur aux étiquettes de \(g_b\), elles-mêmes plus grandes que celles de \(d_a\), il vient que y est supérieur aux étiquettes de l’ABR résultant de la fusion.
- Or \(y\) est inférieur aux étiquettes de \(d_b\) puisque \(b\) est un ABR. Donc \(d = N(y , merge(d_a, g_b), d_b)\) est un ABR dont toutes les étiquettes sont aumoins plus grandes que celles de la plus petite de \(d_a\). De plus il contient \(y\) et toutes les étiquettes de \(d_a, g_b, d_b\).
- Donc \(x\) est plus petit que les étiquettes de \(d\) (qui est un ABR) et plus grand que celles de \(g_a\) (qui est un ABR) donc \(N(x, g_a, d)\) est un ABR avec toutes les étiquettes de \(a, b\).
Complexité de la fusion¶
Soient deux ABR \(g , d\) :
- Il y a au plus autant d’appels internes que le minimum de hauteur des sous arbres.
- La complexité est en \(\Theta(\min(h(g), h(d)))\) où \(h(g)\) et \(h(d)\) sont les hauteurs respectives de \(a, b\).
- La fusion est une fonction auxiliaire utilisée dans le cadre de la supression d'un noeud d'étiquette donnée. Dans ce cas, les deux arbres à fusionner sont des sous-arbres de l'ABR initial. En notant \(h\) la hauteur de l'ABR initial, on a \(h(g) = O(h)\) et \(h(d) = O(h)\). Il vient donc que la fusion a une complexité temporelle en \(\Theta(h)\)
Code¶
Remarques
Lorsque le nœud \(A\) d’étiquette \(x\) n’a qu’un fils, celui-ci prend la place de son père (on le "remonte").
Si \(A\) est une feuille, on se contente de la supprimer (la fusion met Empty à la place de \(A\)).
Rotations¶
Rotation droite¶
Soit un ABR avec \(2\) noeuds contenant les valeurs \(u,v\) et \(3\) sous-arbres \(t_1, t_2, t_3\)
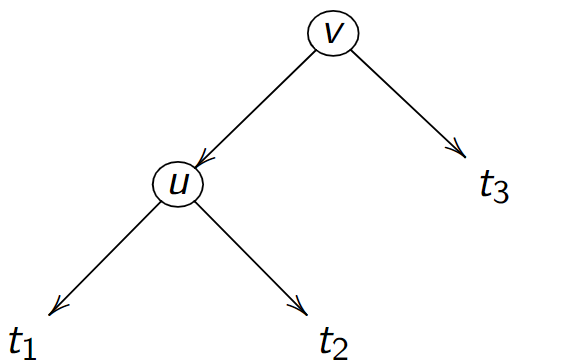
On a (en notant de façon abusive) \(t_1 < u < t_2 < v < t_3\)
On peut réorganiser l'arbre en conservant la propriété d'ABR :
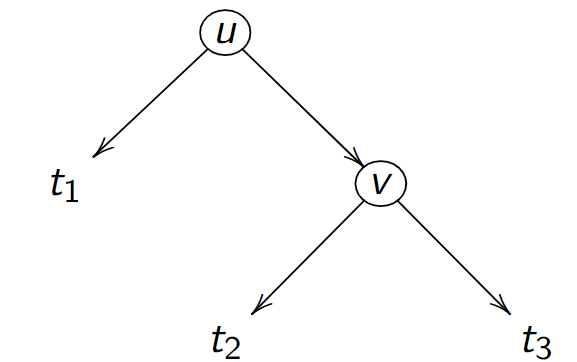
L'inégalité \(t_1 < u < t_2 < v < t_3\) assure qu'il s'agit bien d'un ABR; Cette transformation s'appelle rotation droite (car les 2 noeuds \(u, v\) ont été déplacés vers la droite).
Rotations droite et gauche¶
L'opération inverse est également possible
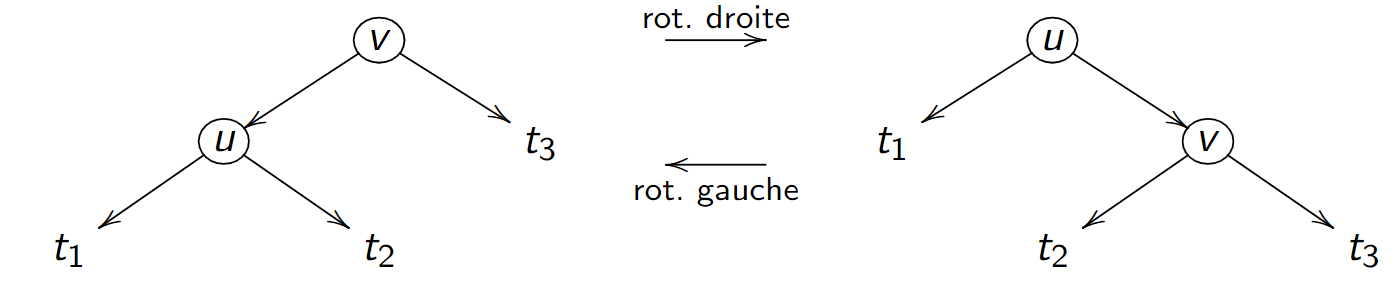
Rééquilibrage¶
- Ces deux rotation constituent l'outil principal de rééquilibrage des ABR.
- Lorsqu'un arbre se retrouve déséquilibré parce qu'il commence à "trop pencher d'un côté", on utilise une ou plusieurs rotations pour le ramener à un arbre plus équilibré.
Dictionnaires¶
Dictionnaire¶
Définition: Tableau associatif
Tableau associatif (aussi appelé dictionnaire ou table d’association) : type de données associant à un ensemble de clefs un ensemble correspondant de valeurs.
Chaque clef est associée à une valeur unique : un dictionnaire correspond donc à une application en mathématiques.
Il peut être vu comme une généralisation du tableau dont les indices ne serait pas nécessairement des entiers.
Opérations usuellement fournies¶
- ajout : association d’une nouvelle valeur à une nouvelle clef ;
- modification : association d’une nouvelle valeur à une ancienne clef ;
- suppression : suppression d’une clef ;
- recherche : détermination de la valeur associée à une clef, si elle existe.
Les dictionnaires peuvent être implémentés concrètement par des ABR. Ce sont alors des données persistantes. L’ensemble des clés doit être totalement ordonné. Les étiquettes des nœuds de l’ABR sont des couples (clés, valeurs) et le placement d’un nœud dans l’arbre est fait selon sa clé et non sur sa valeur. En OCaml, explorons \(3\) façons de définir les dictionnaires.
Implémentation de dictionnaire¶
Les dictionnnaires peuvent être implémentés concrètement par des ABR. Ce sont alors des données persistantes.
L'ensemble des clés doit totalement être ordonné.
Les étiquettes des noeuds de l'ABR sont des couples (clés, valeurs) et le placement d'un noeud dans l'arbre est fait selon sa clé et non sa valeur.
En OCaml, explorons \(3\) façons de définir les dictionnaires.
Dictionnaires par liste de paires¶
Méthode la plus simple. Persistante.
Dictionnaires par AVL¶
- Les arbres AVL ont été historiquement les premiers arbres binaires de recherche automatiquement équilibrés.
- Dans un arbre AVL, les hauteurs des deux sous-arbres d’un même nœud diffèrent au plus de un.
- La recherche, l’insertion et la suppression sont toutes en \(O(\log_{2}(n))\) dans le pire des cas.
- L’insertion et la suppression nécessitent d’effectuer des rotations (opérations de rééquilibrage).
Le nom AVL vient des deux inventeurs Georgii Adelson-Velsky et Evguenii Landis (1962).
Structure persistante basée sur les arbres équilibrés. Ajout/Suppression/Recherche en temps logarithmique.
Dictionnaires par table de hachage¶
Structure impérative. Modifications en place. Ajout/Suppression/Recherche en temps constant (en moyenne pour ajout, et pour la recherche, ça dépend en fait de la fonction de hash).
Tas¶
Généralités¶
Définition: Tas
Un tas de hauteur h est un arbre binaire vérifiant :
- Condition d’ordre : les fils d’un nœud ont une étiquette inférieure ou égale à celle du père.
- Condition de structure: Un tas est complet gauche :
- Tous les niveaux sont remplis sauf éventuellement le dernier.
- Le dernier niveau (éventuellement incomplet) est rempli sans trou enpartant de la gauche.
Précisions et conséquences¶
- Un arbre du type précédent est dit de type tas-max (racine=max).
- tas-min : l’étiquette du père est plus petite que celle des fils.
- Les branches sont toutes de longueur \(h\) ou \(h − 1\),
- enlever les feuilles de profondeur \(h\) donne un arbre parfait,
- les nœuds internes de profondeur \(h − 1\) d’arité \(≥ 1\) sont à gauche des feuilles de profondeur \(h − 1\),
- si il y a un nœud interne de profondeur \(h − 1\) avec un seul fils, son fils est une feuille et c’est le dernier nœud dans le parcours en largeur.
Figure – Un tas. Si on enlève les feuilles de profondeur \(2\), l’arbre est parfait
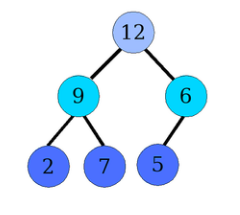
(cf figure dans la section Tas et Tableaux pour la représentation en array)
Tous les niveaux sont remplies, sauf le dernier, lequel est partiellement rempli en commençant par la gauche.
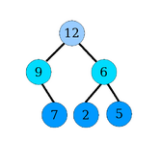
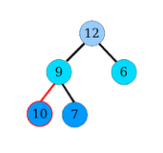
Contre-exemples
Les arbres suivants ne sont pas des tas :
Hauteur d’un arbre complet gauche¶
Soit \(A\) un arbre complet gauche à \(n\) nœuds et de hauteur \(p\)
- L’avant dernier niveau (qui correspond à un arbre parfait) est rempli. Et le dernier niveau contient au moins une feuille.
Représentation par tableaux¶
Exemple
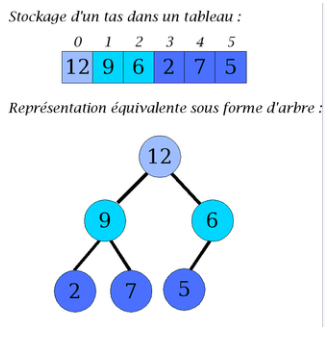
Observer le lien entre le parcours en largeur et la représentation en tableau.
Contrexemples
Les arbres suivants ne sont pas des tas :
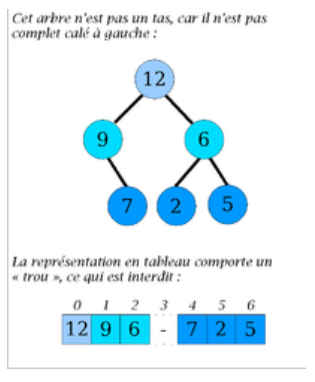
Figure – Un nœud de hauteur \(h − 1\) et d’arité \(1\) est à gauche d’un nœud de hauteur \(h − 1\) d’arité \(2\)
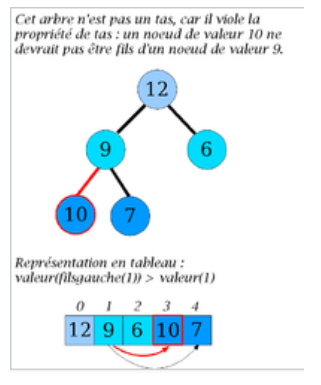
Figure – Un père a un fils d’étiquette plus grande que la sienne
Tas et tableaux¶
On peut stocker un tas dans un tableau dont on n’utilise pas (pour le moment) le premier élément.
- La racine occupe l’élément d’indice \(1\),
- Les fils du nœud d’indice \(k\) (avec \(k > 0\)) sont aux indices \(2k\) et \(2k + 1\) (si ceux-ci ne dépassent pas la longueur du tableau).
- Le père du nœud d’indice \(k\) est à l’indice \(\lfloor k/2 \rfloor\).
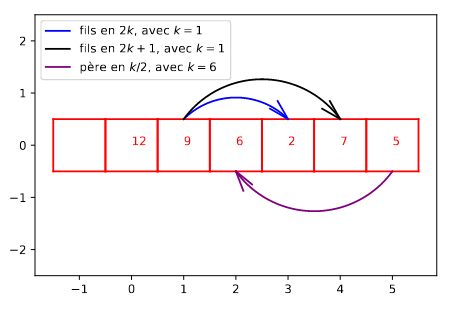
Figure – Relations père/fils dans un tableau représentant un tas
En OCaml¶
Lorsqu’on crée un tableau représentant un tas :
- Il faut prévoir la taille du tableau à l’instant initial (\(6\) ici) et les éventuels ajouts à effectuer (en clair prévoir plus de place que la simple taille du tableau à l’instant \(0\)).
- Le premier élément du tableau désigne la taille du tas (qui est différente de celle du tableau).
- Les éléments \(0\), \(67\), \(33\) en fin de tableau ne sont pas considérés comme appartenant au tas. Ils seront remplacés par les valeurs éventuellement ajoutées au tas.
Un problème
Le type de la taille du tas (int) fige le type du tableau avec l’implémentation précédente. Toutes les valeurs du tas doivent être des entiers...
Une solution
Opérations¶
Opérations sur les tas¶
- Ajouter : ajout d’un élément dans le tas binaire en préservant la structure de tas.
- Retirer : retirer un élément d’indice donné et rectifier le tableau pour qu’il corresponde de nouveau à un tas.
- Construire : construction du tas binaire à partir d’un ensemble d’éléments.
Ajouter un élément¶
Principe¶
Considérons que l’on veuille ajouter le nœud \(x\) à notre tas binaire :
- On insère \(x\) à la prochaine position libre (la position libre la plus à gauche possible sur le dernier niveau),
- puis on effectue l’opération suivante (que l’on appelle percolation vers le haut ou percolate-up) pour rétablir si nécessaire la propriété d’ordre du tas binaire :
- Tant que \(x\) n’est pas la racine de l’arbre et que l’étiquette de x est strictement supérieure à celle du père, échanger les positions entre x et son père.
Shéma de l'ajout¶
Exemple
On veut ajouter \(50\) dans un tas-max :
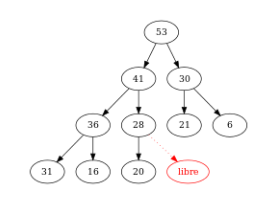
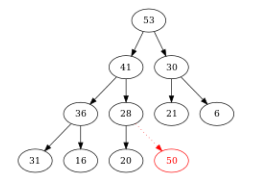
Figure – le nœud d’étiquette \(50\) est placé provisoirement. On le compare à son père \((28)\)
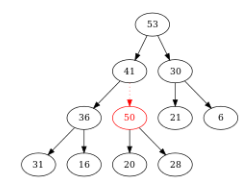
Figure – Comme \(50 > 28\), on échange les positions de \(50\) et \(28\). Et on compare \(50\) avec son nouveau père \((41)\)...
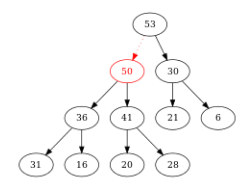
Figure – Comme \(50 > 41\), on échange les positions de \(50\) et \(41\). Et on compare \(50\) avec son nouveau père \((53)\)...
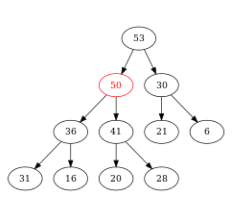
Figure – Comme \(50 ≤ 53\), il n’y a rien à faire : \(50\) a trouvé sa bonne place
La fonction auxiliaire d’échange¶
Complexité en \(\Theta(1)\).
La fonction auxiliaire de percolation¶
Complexité de la percolation haute¶
On applique cette fonction à un tas d’entiers de \(n\) nœuds (représenté par un tableau) :
- Dans le pire des cas, l’élément remonte la branche la plus longue du tas : \(\log_2(n)\) étapes puisque le tas est un arbre binaire presque parfait.
- À chaque étape, il y a un nombre borné \(c\) d’opérations élémentaires.
- Au total, entre \(\log_2(n)\) opérations et \(c\log_2(n)\). Complexité en \(\Theta(\log_2(n))\).
La fonction d’insertion¶
Principe
On insère l’élément après le dernier élément du tableau (\(\Theta(1)\)) et on percole (au pire \(\Theta(\log_2(n))\)) si \(n\) est le nombre de nœud). Donc complexité au pire \(\Theta(\log_2(n))\):
Supprimer un élément¶
Shéma de la suppression¶
Schema
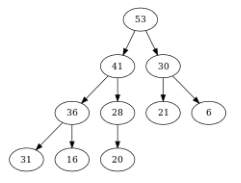
Figure – Le tas-max de référence
On souhaite supprimer la racine du tas-max suivant :
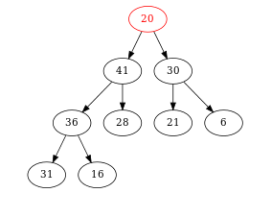
Figure – On remplace la racine par le dernier nœud
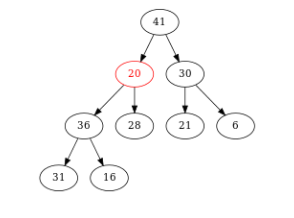
Figure – On compare \(20\) et son fils max \((41)\). Comme \(41 > 20\), on échange \(41\) et \(20\)
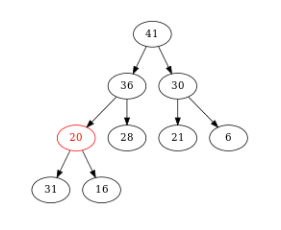
Figure – On compare \(20\) et son fils max \((36)\). Comme \(36 > 20\), on échange \(36\) et \(20\)
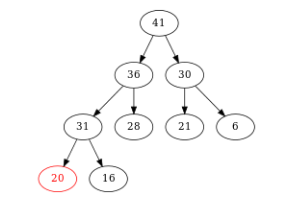
Figure – On compare \(20\) et son fils max \((31)\). Comme \(31 > 20\), on échange \(31\) et \(20\). On est alors dans un des deux cas d’arrêt : plus de fils ou pas de fils plus grand. Ici, \(20\) n’a plus de fils. On a fini.
Principe de suppression¶
On veut supprimer la racine :
- Lorsqu’on supprime le dernier nœud d’un tas, celui-ci reste un tas.
- On supprime le dernier nœud et on le met à la place du nœud racine (la propriété d’ordre est perdue).
- On percole vers le bas (percolate-down) pour retrouver la propriété d’ordre.
Recherche du plus grand fils¶
Complexité en \(O(1)\).
Percolate-down¶
Complexité de la percolation basse¶
- À chaque appel interne on descend d’un étage dans l’arbre.
- Le nombre d’appel est majoré par la hauteur ( \(\log_2(n)\) pour \(n\) nœuds dans cet arbre complet gauche).
- A chaque appel interne, il y a moins de \(c\) opérations élémentaires.
- Coût total entre \(\log_2(n)\) et \(c\log_2(n)\). ODG \(\Theta(\log_2(n))\)
Supprimer la racine¶
Complexité : la même que la percolation.
Création¶
Par remontée : percolation haute du nœud courant¶
-
Pour \(t\), tableau de taille \(n\), on fait une copie de taille assez grande, disons n+1 : $$ \begin{array}{|c|c|c|} 6 & 12 & 8 & 7 & 15 & → & \color{red}{5} & 6 & 12 & 8 & 7 & 15 \ \end{array} $$ Et on maintient "\(t[1:k+1]\) est un tas" (notation slicing Python).
-
\(k = 1\) : $$ \begin{array}{|c|c|c|} 5 & \color{red}6 & 12 & 8 & 7 & 15 \end{array} $$ \(t[1:2]\) est un tas
-
\(k = 2\) :
\begin{array}{|c|c|c|} 5 & \color{red}6 & \color{red}12 & 8 & 7 & 15 \end{array} On percole up \(12\). \begin{array}{|c|c|c|} 5 & \color{red}12 & 6 & \color{red}8 & 7 & 15 \end{array} t[1:3] est un tas. -
\(k = 3\) : \(8\) est à sa place. \(t[1:4]\) est un tas.
-
\(k = 4\) : \begin{array}{|c|c|c|} 5 & 12 & \color{red}6 & 8 & \color{red}7 & 15 \end{array} On percole up \(7\) : \begin{array}{|c|c|c|} 5 & 12 & \color{red}7 & 8 & \color{red}6 & 15 \end{array} \(t[1:5]\) est un tas.
-
\(k = 5\) : \begin{array}{|c|c|c|} 5 & 12 & \color{red}7 & 8 & 6 & \color{red}15 \end{array} On percole up \(15\) deux fois \begin{array}{|c|c|c|} 5 &12 &\color{red}15 &8 &6 &\color{red}7 \end{array} \begin{array}{|c|c|c|} 5 &\color{red}12 &\color{red}15 &8 &6 &7 \end{array} \begin{array}{|c|c|c|} 5 & \color{red}15 & \color{red}12 & 8 & 6 & 7 \end{array} \(t[1:6]\) est un tas.
Complexité de la création du tas par remontée¶
Il y a \(n\) nœud, donc une hauteur de \(p=\lfloor \log_2(n) \rfloor\).
Pire des cas : chaque remontée aboutit à la racine.
Niveau \(k\) : au plus \(2^k\) nœuds remontent à la racine en \(k\) étapes.
Par descente : percolation basse du nœud courant¶
A partir d’un tableau d'entiers :
- On le considère comme un arbre complet gauche en décalant ses éléments d’un cran à droite et en insérant sa longueur.
- Parcours du tableau : on maintient l’invariant Tous les sous-arbres dont la racine est à droite du sommet courant sont des tas binaires.
- On parcourt les sommets par indices décroissants à partir du premier noeud interne (position \(\lfloor \frac{n}{2} \rfloor\))
-
Donc après avoir traité la racine, comme elle vérifie l’invariant, notre arbre est un tas binaire.
-
Pour \(t\), tableau de taille \(n\), on fait une copie de taille disons \(n+1\) \begin{array}{|c|c|c|} 6 & 12 & 8 & 7 & 15 & 9 & → & \color{red}6 & 6 & 12 & 8 & 7 & 15 & 9 \end{array} \(7,15, 9\) aux indices > \(\lfloor \frac{n}{2}\rfloor\) sont des feuilles donc des tas.
- \(k=\lfloor \frac{n}{2}\rfloor = 3\) (Profondeur \(1\)). \(8\) est le père de \(9\). \begin{array}{|c|c|c|} 6 & 6 & 12 & \color{red}8 & 7 & 15 & \color{red}9 & → & 6 & 6 & 12 & \color{red}9 & 7 & 15 & \color{red}8 \end{array}
- \(k = 2\) (Profondeur \(1\)). \(12\) est père de \(7\) et \(15\) \begin{array}{|c|c|c|} 6 & 6 & \color{red}12 & 9 & 7 & \color{red}15 & 8 & → & 6 & 6 & \color{red}15 & 9 & 7 & \color{red}12 & 8 \end{array}
- \(k = 1\) (Profondeur \(0\)). \(6\) est père de \(15\) et \(9\). \(2\) percos. \begin{array}{|c|c|c|} 6 & \color{red}6 & \color{red}15 & 9 & 7 & \color{red}12 & 8 & → & 6 & \color{red}15 & \color{red}6 & 9 & 7 & \color{red}12 & 8 \end{array} \begin{array}{c|c|c|} → 6 & \color{red}15 & \color{red}12 & 9 & 7 & \color{red}6 & 8 \end{array}
Complexité de la création du tas par descente¶
Hauteur \(p=\lfloor \log_2(n) \rfloor\) pour \(n\) nœuds.
-
Dans le pire des cas, chaque descente d’un nœud de hauteur \(k\) aboutit aux feuilles : \(p − k\) échanges AU PLUS.
-
Il y a au plus \(\lfloor \frac{n}{2^{p-k}} \rfloor\) nœuds de profondeur \(k\) (cf. TD).
-
Complexité \(C(n)\) au pire :
Donc création par descente moins coûteuse (\(O(n)\)) que par remontée (\(O(n \log_2(n))\)).
Tri (croissant) par tas¶
A partir d’un tableau de \(n\) nombres \(t\), on crée un tas-max.
- Étape \(1\) : la racine \(t[1]\) est le maximum du tas, on l’échange avec \(t[n]\) (notation Python). Le max se retrouve à la fin du tas en position \(t[n]\). \(\color{red}t[n:] \text{ est trié et contient le max.}\)
- On met à jour la longueur du tas (qui représente le nombre d’éléments qu’il reste à trier) en la décrémentant (puisque l’ancienne racine a trouvé sa place). \(t[:n]\) est un tas.
- On percole bas la nouvelle racine. \(\color{red}\text{Alors t[1:n] est de nouveau un tas}\). Et on itère(swap puis percolation)...
- L’invariant qui assure la correction est "À la fin de l’étape \(k\), \(\color{red}\text{t[:n-k+1] est un tas et t[n-k+1 :] est un tableau trié}\) par ordre croissant dont les éléments sont plus grands que ceux de \(t[:n-k+1]\)". Il y a \(n\) étapes.
Tri par tas¶
Complexité¶
- \(O(n)\) pour la création d’un tas (rappel : hauteur \(O(\log_2(n))\)).
- Chaque échange d’éléments et chaque décrémentation de \(t.(0)\) en \(O(1)\)
- Chaque appel à
percolate downen \(O(\log_2(n))\) (majoration grossière car la longueur du tas décroît). - \(n\) passages dans la boucle.
- Complexité au pire en \(O(n\log_2(n))\) à la louche.
- On ne peut pas faire mieux pour un tri par comparaison. Donc complexité en \(\Theta(n\log_2(n))\)
Files de priorités (une application des tas)¶
Définition : Une file de priorité
Une file de priorité est une structure de données permettant de stocker des éléments et de retrouver efficacement celui qui a la plus haute priorité.
Il y a trois primitives :
- insérer un élément ;
- extraire l’élément ayant la plus grande clé ;
- tester si la file de priorité est vide ou pas.
- On ajoute parfois à cette liste l’opération "augmenter/diminuer" la clé d’un élément", utilisée par exemple dans l’algorithme de Dijkstra.
Les priorités sont d’un type totalement ordonné.
Une file de priorité permet d’implémenter efficacement des planificateurs de tâches, où un accès rapide aux tâches d’importance maximale est souhaité.
On trouve une file de priorité, par exemple, dans les ordonnanceurs des systèmes d’exploitation, notamment le noyau \(Linux\).
Les urgences d’un hôpital
- Chaque nouveau patient est ajouté à la file,
- chaque fois qu’un médecin est libre, il s’occupe du patient avec l’état le plus critique.
- Le tri des patients se fait sur des critères quantifiables et ordonnés comme
- comme l’état de conscience : Échelle de Glasgow \([\![1,4]\!]\times[\![1,5]\!]\times[\![1,6]\!]\) (priorité aux scores bas, ce qui entraîne d’utiliser un tas-min)
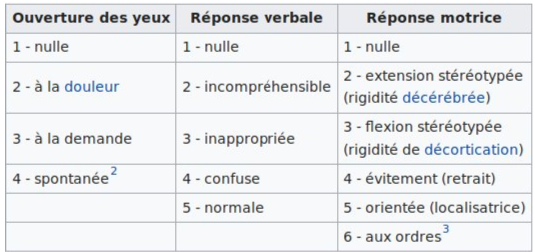
- s’ils respirent (\(1\) ou \(0\)), ou s’ils saignent (volume de la perte de sang)...
Type de données pour la file de priorité¶
Comme le tas est un tableau de données (type data), on ne peut plus réserver le premier élément à l’indication de sa longueur(type int).
Toutefois, on a pris l’habitude de stocker les données à partir de l’élément \(1\) et non \(0\). Donc nos tableaux auront une première case qui ne servira à rien.
La longueur du tas est toujours susceptible d’évoluer. Il faut la définir comme mutable.
f.n+1 désigne la première case libre du tas f.tbl.
Primitives pour la file de priorité¶
Création d'une file de priorité¶
Exceptions¶
On peut ajouter des éléments dans la file tant qu’elle n’est pas pleine. Si elle est pleine, on soulève une exception Full.
On peut retirer des éléments de la file tant qu’elle n’est pas vide. Si elle est vide, on soulève une exception Empty.
Création des exceptions :
Ajouter¶
Il faut adapter la fonction de percolation haute à nos priorités. En exo.
Retirer¶
Il faut adapter la fonction de percolation basse à nos priorités. En exo.
Augmenter la priorité¶
Quand on augmente l’urgence, donc qu’on diminue la valeur de priorité d’un élément, on le fait remonter par percolation haute.
Et quand on diminue l’urgence, on fait descendre l’élément par percolation basse. Il peut être utile de maintenir dans la structure un dictionnaire qui indique, pour chaque valeur, à quelle position on peut la trouver.